
The AI VAR
How AI-Native Teams Verify What Matters Without Slowing Everything Down

During a World Cup match, nobody wants VAR to interrupt every pass, tackle, or throw-in.
But nobody wants a match-changing error to go unreviewed either.
Education faces a similar tension.
Assessment should be embedded throughout the process—not as constant interruption, but as an intentional practice with a clear purpose, explicit criteria, and relevant evidence. Its role is not merely to judge performance at the end, but to make progress visible, generate meaningful feedback, and guide timely improvement while learning is still taking place.
AI-native work has the same design problem:
How do we increase speed without allowing critical errors to move faster?
This is the fifth article in The Human-AI Playbook.
So far, we have argued that:
- 11 agents are not a team.
- The first bad match is not failure.
- The same playbook will not work for every team.
- If you measure only AI usage, you are watching the ball—not the game.
Now we need to address what happens after AI begins producing real work:
What can move automatically? What requires review? What must be escalated? And who remains accountable for the final decision?
That is the role of the AI VAR.
Not every play needs VAR
AI-assisted delivery can fail in two opposite ways.
The first is to review almost nothing.
The team moves quickly, but defects, incorrect assumptions, test gaps, scope drift, policy violations, and fragile decisions move downstream.
The second is to review everything with the same intensity.
Every AI-assisted artifact enters a slow approval process. Every minor change requires several people. The organization adds so much control that it destroys the speed AI was supposed to create.
Neither approach works.
A typo correction should not require an architecture committee.
A production change involving authentication, personal data, or financial logic should not pass with a casual glance.
The purpose of verification is not to review everything.
It is to identify what can change the game—and apply the right control before it does.
Not every play needs VAR. But every team must know which plays cannot go unreviewed.
Why “human in the loop” is too vague
Many organizations say they have a “human in the loop.”
That phrase sounds reassuring.
But it often leaves the most important questions unanswered:
- Which human?
- At what stage?
- With what expertise?
- With access to what context?
- Using which criteria?
- Reviewing what evidence?
- With authority to approve, reject, or escalate?
- Accountable for which consequence?
A person who lacks context, time, criteria, or authority is not a meaningful control.
They are a signature at the end of an uncontrolled process.
In AI-assisted work, human presence and human oversight are not the same thing.
A useful reviewer must be able to answer:
What was the intended outcome?
What did AI actually produce?
What evidence supports the output?
What assumptions were introduced?
What changed beyond the declared scope?
What risk would remain if this were accepted?
Do I have the authority and expertise to approve it?
If those questions cannot be answered, “human in the loop” may become little more than organizational theater.
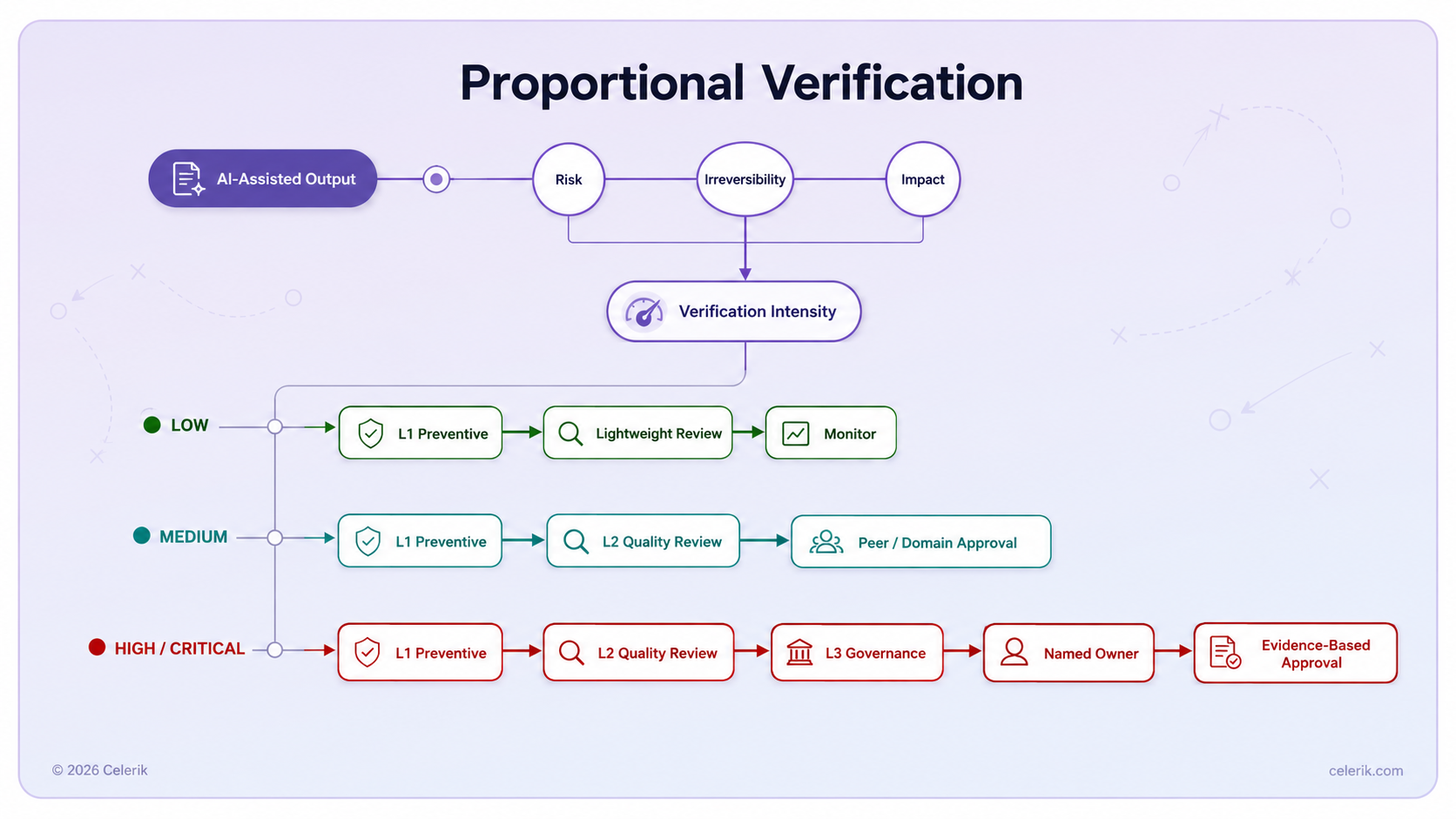
Three variables should determine verification intensity
Before deciding how an AI-assisted output should be reviewed, teams should evaluate three variables.
Risk
What could go wrong?
The consequence could be small:
- inconsistent formatting,
- duplicated code,
- incomplete documentation.
Or it could be significant:
- a functional defect,
- an architectural inconsistency,
- a privacy exposure,
- an incorrect customer response,
- a regulatory or financial impact.
Reversibility
How easily can the decision be corrected?
Some outputs are inexpensive to undo.
Others create expensive migrations, contractual commitments, production effects, customer harm, or irreversible disclosures.
Impact
Who or what is affected?
An internal draft does not have the same impact as production code.
A local prototype is not the same as a customer-facing workflow.
A low-risk test fixture is not the same as a change involving authentication, authorization, personal data, or financial calculations.
A useful decision principle is:
Verification Intensity = Risk × Irreversibility × Impact
This is not intended as a mathematically precise formula.
It is a routing rule.
The higher the combined risk, irreversibility, and impact, the stronger the required evidence, reviewer authority, and governance path.
NIST’s Generative AI Profile similarly frames risk management as a set of actions that should align with an organization’s goals, priorities, and particular generative-AI risks—not as a single universal control applied to every use case. (NIST)
Proportional verification
From spec-driven execution to traceable verification
Verification becomes more reliable when the reviewer can compare the output against an explicit statement of intent.
This is one reason spec-driven development matters in AI-assisted software delivery.
GitHub describes Spec-Driven Development as a model in which specifications become executable rather than serving only as disposable documentation. Its structured flow includes governing principles or a constitution, a specification, an implementation plan, tasks, and execution. (GitHub)
At Celerik, we have adapted that foundation into a broader delivery process.
Product owners participate in defining intent, requirements, acceptance criteria, and the initial plan. They answer a Celerik-developed sequence of questions layered on top of GitHub Spec Kit so that the specification reflects the business problem rather than merely producing technical tasks.
The structured flow then runs through self-hosted Azure DevOps agent pools.
Azure DevOps manages work items, orchestration, execution evidence, and pipeline activity. AI agents support implementation, testing, documentation, and review. GitHub Copilot supports PR review. Human developers and Tech Leads retain ownership of technical decisions and final approval.
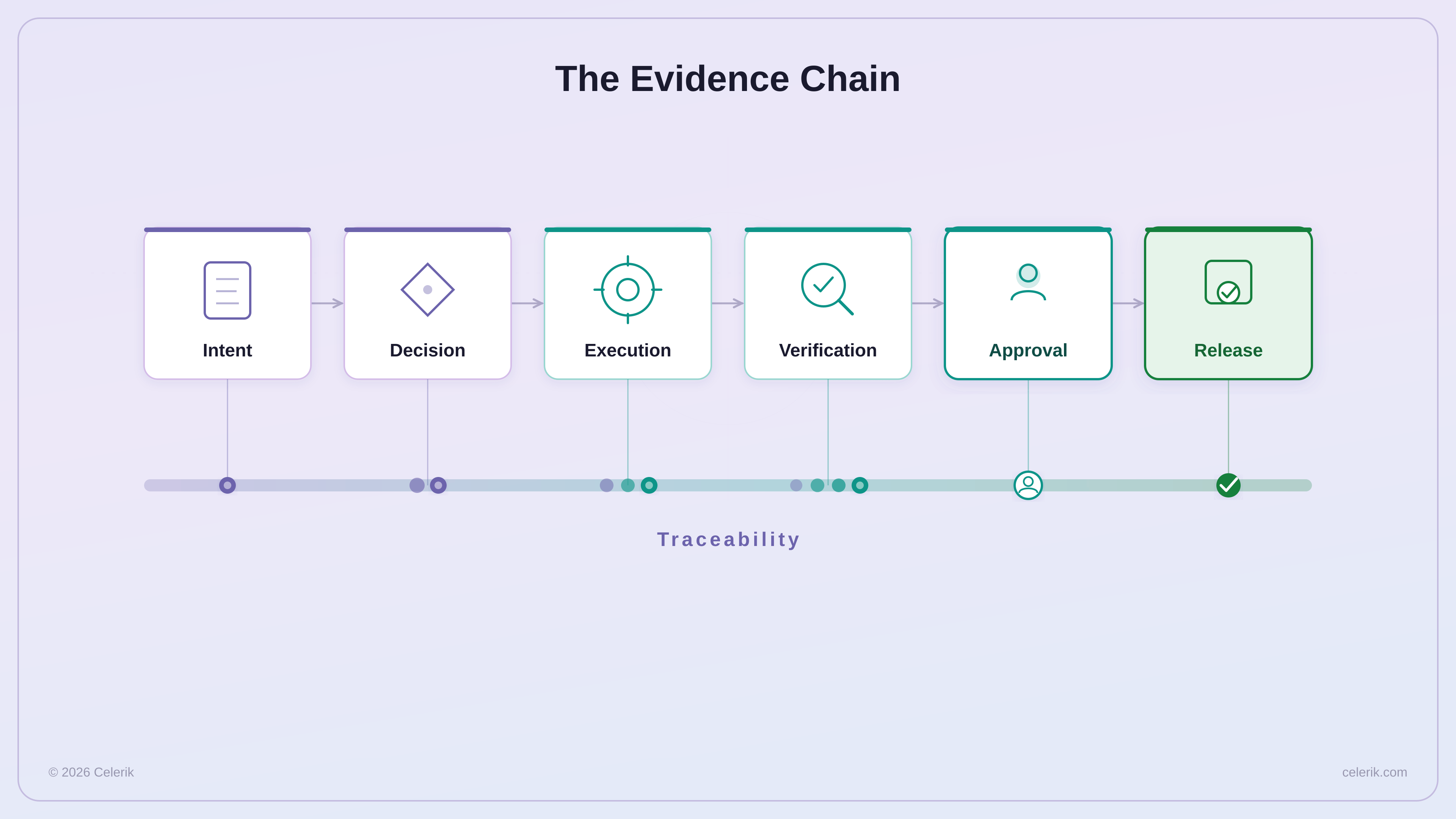
This gives us an evidence chain:
Business Intent
→ Constitution
→ Specification
→ Plan
→ Work Item
→ AI-Assisted Execution
→ Tests
→ Pull Request
→ Review Findings
→ Human Decision
→ Release Evidence
The purpose is not to preserve every conversation indefinitely.
The purpose is to preserve enough structured evidence to answer:
What did we intend to do?
What did the system actually do?
How was it tested?
What was reviewed?
Who approved it?
What evidence supports the release?
QMING: making quality observable
At Celerik, this verification architecture is implemented and continuously refined through QMING, our quality-management and governance layer for traceable AI-assisted delivery.
QMING is not intended to add a final bureaucratic checkpoint after the work is complete.
Its purpose is to make quality observable throughout the delivery flow.
It connects:
- preventive controls,
- AI-assisted technical review,
- human judgment,
- governance gates,
- traceability,
- and release evidence.
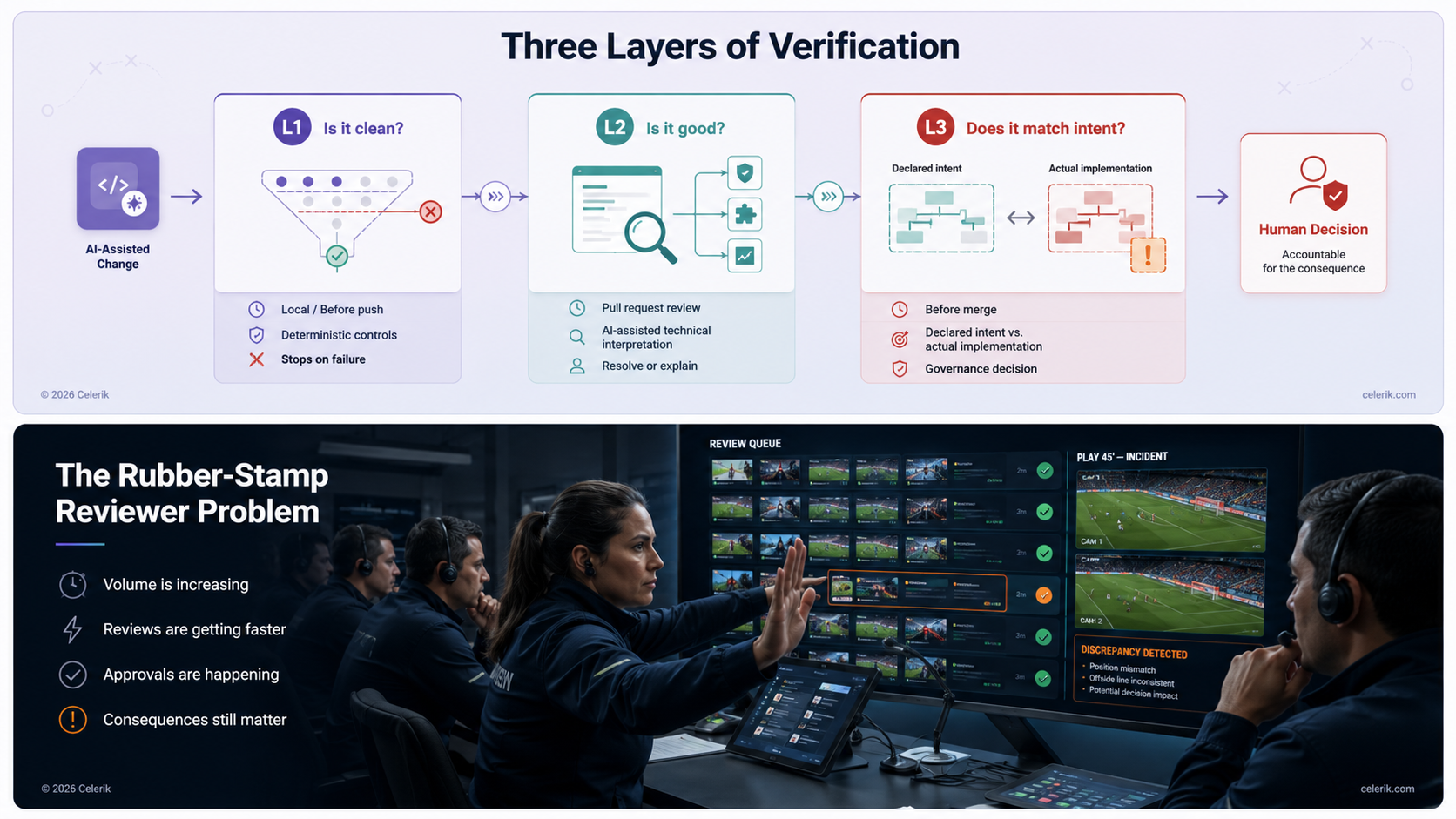
The current model uses three layers.
Each layer asks a different question.
L1 — Preventive Controls
Is it clean?
L1 handles problems that should be detected deterministically and as early as possible.
Typical controls include:
- formatting,
- linting,
- static analysis,
- secrets detection,
- unsafe imports,
- dependency checks,
- baseline security hygiene,
- policy-as-code checks,
- required metadata,
- basic test execution.
These controls run locally, before commit or push, and can also run inside CI.
When L1 fails, the push or pipeline should stop until the problem is corrected.
The principle is simple:
If a machine can check something reliably, do not spend scarce human judgment checking it repeatedly.
Catching deterministic issues early also prevents them from consuming cloud review resources or creating unnecessary review noise later.
Celerik is also exploring a lightweight local PR-review step—potentially using a local model—to identify obvious quality signals, risky changes, or performance smells before sending the work to cloud-based review. The goal is to provide faster and more private feedback while reducing unnecessary token consumption.
In football terms, L1 covers the objective conditions that should not require interpretation: player eligibility, field conditions, equipment rules, or a ball clearly crossing the line.
L2 — Assisted Quality Review
Is it good?
Passing L1 means the artifact is mechanically clean.
It does not mean it is good.
L2 examines technical quality and asks questions that require interpretation:
- Is the design maintainable?
- Does the implementation fit the architecture?
- Are important edge cases missing?
- Are the tests sufficient?
- Does the solution introduce unnecessary complexity?
- Are performance concerns visible?
- Are there insecure or fragile patterns?
- Are assumptions undocumented?
- Could the code be simpler or clearer?
In Celerik’s current flow, GitHub Copilot supports PR review through the Azure DevOps pipeline.
QMING can apply different reviewer modes depending on the project’s needs:
- Strict: maximize coverage and identify everything that could be improved.
- Audit: focus on risk, critical debt, and demanding technical scrutiny.
- Balanced: prioritize quality, maintainability, and delivery pragmatism.
- Pragmatic: report what materially matters without overwhelming the team.
The output is advisory rather than automatically blocking in every case.
But findings cannot simply disappear.
The developer or Tech Lead should either:
- correct the issue,
- accept a recommendation,
- or document why the recommendation does not apply.
AI assists the review.
A qualified human owns the technical judgment.
In football terms, L2 resembles the combination of assistant referees, replay analysis, and experienced interpretation. Several signals contribute to understanding what happened, but expertise is still required to judge the play.
L3 — Governance and Intent Alignment
Is what we did what we said we would do?
L3 is the distinctive governance layer.
A technically valid implementation can still be the wrong implementation.
The code may compile.
The tests may pass.
The implementation may even look well designed.
But it may not match the approved intent.
L3 compares what the team declared it would do—through the specification, work item, plan, PR title, and PR description—with what actually changed in the diff.
It looks for patterns such as:
- scope drift,
- changes outside the declared feature,
- modifications to sensitive areas without notice,
- omitted restrictions,
- missing test coverage,
- mismatches between the implementation and acceptance criteria,
- changes to files that the plan never identified,
- work-item misalignment,
- missing release evidence.
We have seen why this layer is necessary.
A specification may correctly define the intended outcome. A plan may be generated according to a structured Spec Kit-inspired workflow. Yet during implementation, an agent may modify additional files, interpret the plan more broadly than intended, omit a constraint, or leave a test gap.
Without L3, each individual change may appear reasonable.
Only the comparison between declared intent and actual implementation reveals the divergence.
A simple example:
The PR says it updates a user-interface behavior.
But the diff also changes database mappings, authentication configuration, or unrelated service files.
That does not automatically mean the changes are wrong.
It means they require explanation and potentially a separate approval path.
Another example:
The specification requires backward compatibility and explicit regression tests.
The implementation works for the new path but silently omits the compatibility constraint or the required evidence.
L3 should identify that mismatch before the merge.
This layer can block the merge when the required evidence or alignment is missing.
Its purpose is governance, not stylistic code review.
In football terms, VAR is not deciding whether a player’s movement was elegant.
It is deciding whether a match-changing action complied with the rules and whether the original decision should stand.
Verification is an evidence chain—not a meeting
Weak verification often depends on one final conversation:
“Does this look okay?”
Strong verification relies on evidence collected throughout the workflow.
At Celerik, that evidence currently includes elements such as:
- the specification link,
- the Azure DevOps work item,
- the implementation scope,
- the agents or execution steps that ran,
- test results,
- the PR summary,
- review findings,
- human approval,
- and release evidence.
The reviewer should not need to reconstruct intent from memory or infer it from the final diff.
The evidence should make it possible to trace:
Intent
→ Decision
→ Execution
→ Verification
→ Approval
→ Release
A review gate is strongest when it can compare artifacts rather than impressions.
Risk-based routing is the next layer
The current L1/L2/L3 architecture is already implemented and being refined.
The next step is to formalize risk classification so that different changes can follow different verification paths.
A possible classification is:
Low risk
Examples:
- internal drafts,
- formatting,
- low-impact documentation,
- reversible test scaffolding,
- isolated non-production experiments.
Typical path:
L1 → Lightweight Review → Monitor
Medium risk
Examples:
- feature implementation,
- integration changes,
- customer-facing content,
- data transformations,
- significant refactoring.
Typical path:
L1 → L2 → Peer or Domain Approval
High or critical risk
Examples include authentication or authorization changes; personal or sensitive data; regulated workflows; financial calculations; architectural exceptions; high-impact production releases; and any change whose consequences would be difficult or impossible to reverse.
Typical path:
L1 → L2 → L3 → Named Decision Owner → Evidence-Based Approval
The classification itself must be adapted to the organization.
Article 3 established that the same playbook will not work for every team. The same principle applies here: verification rules must reflect the organization’s systems, clients, compliance obligations, architecture, and risk tolerance.
AI agents also need operating boundaries
Verification cannot stop at reviewing the final output.
As agents gain access to repositories, pipelines, tools, and organizational data, teams must also govern what agents are allowed to do.
That includes:
- identity,
- permissions,
- tool access,
- execution boundaries,
- data access,
- observability,
- logs,
- and auditability.
Satya Nadella recently described this broader challenge in similar terms: agents need identities, sandboxes, policies, manageability, observability, and ways to audit their work. (Business Insider)
For Celerik, this reinforces the direction of Traceable AI Engineering.
The question is no longer only:
Did the agent produce acceptable code?
It is also:
Which agent acted?
Under which identity?
With access to which tools and data?
What actions did it perform?
Which policies applied?
Can the behavior be reconstructed afterward?
This is where software quality, AI governance, security, and operational accountability begin to converge.
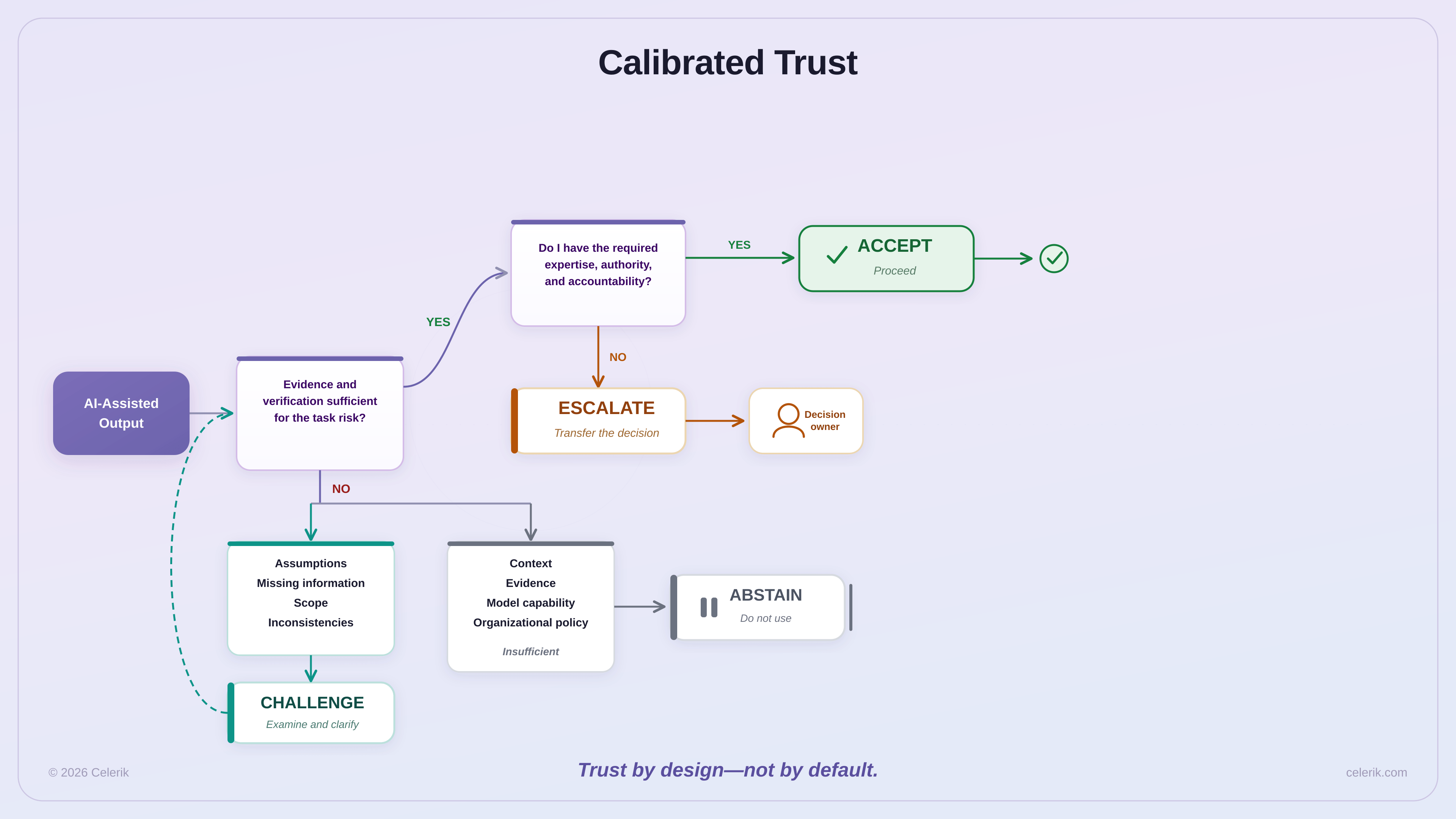
Trust calibration: accept, challenge, abstain, or escalate
The goal of verification is not maximum distrust.
It is not maximum trust either.
The goal is calibrated trust.
A person working effectively with AI needs to choose among four behaviors.
Accept
Use the output when the evidence, task risk, and verification are sufficient.
Challenge
Question assumptions, missing information, recommendations, scope, or inconsistencies.
Abstain
Do not use the output when the context, evidence, model capability, or organizational policy is insufficient.
Escalate
Transfer the decision to someone with the necessary expertise, authority, or accountability.
This is where education, HCI, and software engineering meet.
A person has not developed real AI capability simply because they can generate an output.
Capability becomes visible when they can determine:
- whether the output is sufficient,
- what needs to be checked,
- what remains uncertain,
- when AI should not be used,
- and when another human must enter the process.
In football, good judgment is not always about making the fastest pass.
Sometimes it is knowing when to slow the play, retain possession, or ask the referee to review the decisive moment.
The rubber-stamp reviewer problem
As AI increases the volume of work, review capacity can become the next bottleneck.
When reviewers are overloaded, human oversight can deteriorate into passive approval.
Warning signs include:
- unusually fast reviews of large AI-generated changes,
- repeated “looks good” approvals,
- reviewers without enough domain or architectural context,
- reviewers accountable for outputs they did not understand,
- large mixed-scope PRs,
- no documented reason for overrides,
- repeated issues that gates fail to catch,
- pressure to approve because the change was AI-generated and appears polished.
A review gate that cannot realistically reject the work is not a gate.
It is a ceremony.
Teams can reduce this risk by keeping change batches small, declaring scope explicitly, labeling risk, naming review owners, requiring evidence, protecting time for review, defining escalation paths, and tracking metrics that reveal reviewer overload.
What should the AI VAR measure?
Article 4 introduced the broader AI Scoreboard.
For the AI VAR, we need a focused set of verification metrics.
L1 failure rate
L1 Failure Rate =
Items Failing Preventive Controls / Total Items Checked
This reveals how much preventable noise reaches later review stages.
L2 findings per reviewed item
L2 Findings Density =
Total L2 Findings / Total Items Reviewed at L2
This helps identify recurring quality problems and coaching opportunities.
L3 intent-mismatch rate
Intent-Mismatch Rate =
Items Failing L3 Alignment / Total Items Reviewed at L3
This measures how often actual changes diverge from declared intent.
Review rework rate
Review Rework Rate =
Items Returned for Correction / Total Reviewed Items
Verification tax
Verification Tax =
Additional Review Time
+ Validation Effort
+ AI-Related Rework
Evidence completeness
Evidence Completeness =
Available Required Evidence / Total Required Evidence
Escaped AI defect rate
Escaped AI Defect Rate =
AI-Related Defects Found After Release / AI-Assisted Releases
Override rate
Override Rate =
Review Findings Overridden / Total Review Findings
A high override rate may indicate noisy controls, weak reviewer discipline, or poorly calibrated policies.
Metrics should not become surveillance.
They should help teams improve:
- specifications,
- constitutions,
- agent instructions,
- review policies,
- test strategies,
- reviewer capability,
- and workflow design.
What leaders should ask
Executives do not need to inspect every PR.
But they should know whether the organization has a credible verification architecture.
Useful questions include:
- Which AI-assisted decisions can move automatically?
- Which require human judgment?
- Which require formal governance?
- Who owns the final decision?
- Can reviewers reject the work?
- Is review intensity proportional to risk?
- Are agents operating under defined permissions?
- Can actions and decisions be audited?
- Can we trace implementation back to approved intent?
- Are we measuring verification burden?
- Are we learning from recurring review findings?
- Is the review system protecting quality without destroying delivery speed?
The leadership question is not:
Do we have humans reviewing AI?
It is:
Have we designed a system in which human judgment enters at the right moment, with the right evidence, authority, and accountability?
The fifth principle of The Human-AI Playbook
The first principle was:
11 agents are not a team.
The second principle was:
The first bad match is not failure.
The third principle was:
The same playbook won’t work for every team.
The fourth principle was:
If you measure only AI usage, you are watching the ball—not the game.
The fifth principle is:
Do not review everything equally. Design the review around what can change the game.
AI-native delivery should not choose between speed and control.
It should design verification so that low-risk work can move quickly while consequential work receives the evidence, expertise, and authority it requires.
Trust AI by design—not by default.

Work with us
At Celerik, we are building and refining a practical operating model for traceable AI-assisted software delivery through:
- Human-AI Work Design consulting,
- AI workflow diagnostics,
- Traceable AI Engineering assessments and pilots,
- QMING quality and governance implementation,
- spec-driven delivery design,
- verification architecture,
- and AI capability development.
Our goal is not to add governance after delivery has already happened.
It is to integrate intent, execution, verification, evidence, and human accountability into the workflow itself.
If your organization is accelerating AI-assisted delivery but is uncertain about review burden, traceability, governance, quality, or ownership, the problem may not be a lack of AI capability.
It may be the absence of an AI VAR designed for your system of play.
Follow the series
This article is part of The Human-AI Playbook, a Celerik series about moving from AI tool adoption to Human-AI Work Design.
Published so far:
- 11 Agents Are Not a Team
- The First Bad Match Is Not Failure
- The Same Playbook Won’t Work for Every Team
- The AI Scoreboard
- The AI VAR
Next up:
The Midfield Problem — Why Context Architecture Wins or Loses AI-Native Delivery
Explore the full Human-AI Playbook series:

